PRAGMATEX in XML
To formalize an annotation model in a Schema or DTD in XML language, there is a need to define what information will be introduced in the attribute labels and in the elements label. The application of the annotation model to the Schema is based on the principles below.
The preferred option has been to map the annotation model into the Schema, so that the Schema is linguistically justified. It is impossible to include pragmatic information at the element level due to the lack of hierarchy between the phenomena to be tagged: each phenomenon belongs to a different domain and there is not necessarily a dependency between all of them. For example, in a linguistic form such as: a causa de (because of), we can find two types of pragmatic information: it can be viewed as a phraseological unit, but it also contains information about the discourse relation, more specifically, about reason. If this information would be incorporated as elements instead of as attributes, it could not be possible to systematize the relationship between phenomenon in a consistent way.
As an additional example, a discourse marker can be a phraseological unit but not all the phraseological units are discourse marker. For example, correr el riesgo (to run the risk).
Finally a word could be encoding more than one pragmatic phenomenon simultaneously. For example, the word “por lo visto” (apparently) contain two types of pragmatic knowledge: Therefore, the pragmatic meaning of this particle in (1) is in XML format:
(1) <IP DR= MOD=hedge EVI=3>por lo visto</IP>
<IP DR= MOD=hedge EVI=3>apparently</IP>
In this way, the relation between epistemic modality and evidentiality is reflected.
Clearly the only option is to map the pragmatic knowledge into the Schema for the XML language at attribute level.
The element level of the Schema is utilized to define the text structure and the transcription format tags. Within the CORAL ROM corpus, the text information is coded in two parts: header and transcription. In the header, all contextual information about the communicative interaction is represented without hierarchy: personal data about participants, place, date, numbers of words, length of the conversation, communicative genre, etc. On the other hand, the transcription element is organized under a hierarchy: it is structured in turns, which are made of comments and interventions. Interventions are further differentiated in utterances, which contain as attributed information related to intonations (interrogative, interrupted, non-finished
and ennuntiative) and speech act. Finally utterance can be text, transcription marks (overlaps, paralinguistic signs, etc) and/or pragmatic information.
As follows, a schema of the text elements in XML language is presented:
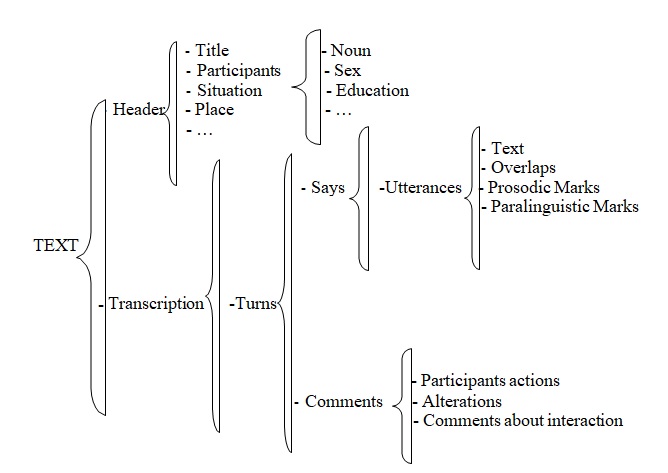
Next, it shows the utterances attributes:

At the attribute level, all pragmatic phenomena are represented. In PRAGMATEXT, pragmatic information must be specified as follows:

The PRAGMATEXT scheme in XML language is detailed in Appendix A.
An example in XML format
Appendix B shows an example of a telephonic conversation tagged in format. In this section, only a fragment of the whole interaction has been include. In it, the speaker makes a phonecall to his friend’s, whose mother explain that his son is currently out.
- *PAD: sí ?
*MIG: andeh / hola / está / Rubén ?
*PAD: andeh / no / no está //
*MIG: ¡ah! / no está ?
*PAD: no //
*MIG: y / sabes cuándo va a llegar ?
*PAD: pues / no tengo ni idea //
- *PAD: hello ?
*MIG: andeh / hello / Rubén is there ?
*PAD: andeh / no / he isn’t here //
*MIG: ¡ah! / isn’t he ?
*PAD: no //
*MIG: and / do you know when he come back?
*PAD: so / I have any idea //
If we analyze this fragment using our annotation model, the following in bold information should be tagged:
- *PAD: sí ?
*MIG: andeh / hola / ¿está / Rubén ?
*PAD: andeh / no / no está //
*MIG: ¡ah! / no está ?
*PAD: no //
*MIG: y / sabes cuándo va a llegar ?
*PAD: pues / no tengo ni idea //
And the pragmatic information of the linguistic forms look as follows:
- sí? → Utterance=Interrogative Speech_Act=asked Modalization=Interactive
- hola → Modalization=Interactive
- andeh → Discourse_Relation=Support
- ¿está Rubén? → Utterance=Interrogative Speech_Act=Ask
- ¡ah! → Modalization=Interactive
- ¿no está? → Utterance=Interrogative Speech_Act=Verify
- y → Discourse_Relation=Addition
- sabes → Modalization=Interactive
- pues → Discourse_Relation=addition
- no tengo ni idea → Modalization=hedge
Finally, this is the pragmatic analysis of turn “¡ah! ¿no está?” in XML format :
<Turn>
<Says Speaker=“MIG”>
<Utterance Prosody=“Interrogative” Speech_Act=“Verify”>
<PI GC=“Interjection” DP=“start” PU=“no” MET=“no” DR=“no” ED=“no” MOD=“Interaction” EVI=“no”>¡ah!</PI>
<Tone_Unit /> no está ?
</Utterance>
</Says>
</Turn>
In Appendix C, the whole conversation tagged in XML is included.

Add Comment